一条被转发1300万次的微博,新浪微博官方的解释
昨天我们报道
新浪微博上有一条抽奖活动的微博被转发了1300多万次,是新浪微博史上转发次数最高的一条微博。经过简单的分析,我们认为这条微博在转发数量上有问题。今天我们从新浪微博官方了解到,他们这个数据是刷出来的,并给出了关于这条微博的数据。
他们在发来的邮件中说:
是活动被刷转发,因为游戏规则没有定义清楚,既没有限定需要加关注,而且还说被转发越多,中奖几率越高,就被人利用了。
情况是这样,一共15万人转发,一共转发1300万次,其中只有3000个是真实用户转发,一共转发9000次。其他均为水军或者机器,目前已经清理干净。
感谢!
被转发了1300万次的微博,其中只有15万人参加,这15万人中只有3000个真实用户,这些真实用户共转发了9000次。这就是这条微博的数据(数据时间截止到10月8号上午10点半左右)。
实际上,当我们昨天
报道这件事时,已经有很多网友关注,并分别以膜拜转发量等微博参与转发,这时这条微博的转发数量已经过了千万。也就是说,真实参与进来的3000多位用户中,有很多是在过了千万次转发之后才转发的这条微博。那么基本上可以判定,在转发数破千万之前,99.99%的用户都是水军或机器。
那么什么样的用户才算是水军或机器?新浪微博官方是如何定义的?我接着向他们的相关负责人问了一些问题。下面是新浪微博相关负责人回复的邮件:
你好
- 请问水军转发和机器转发是怎么定义的?是通过转发多次,还是通过帐号本身属性判定? 水军的帐号基本上都是机器(如一些微博营销软件)在维护,这些帐号从帐号本身的属性和他的访问行为及操作行为上都有一些明显的特征,如帐号的昵称、头像等都具有批量性,访问行为都与正常的浏览器访问行为有明显差异。
2、我看那条微博的转发数现在只有9000多了,这个帐号是否会进行什么样的惩罚处理?还是只默默的将转发数删掉?
这个活动所制定的规则本身就具有缺陷性:“被转发最多的“转发”,前三名每人获得iPid2一部”,必然会有一些人为了刷奖去购买或者制造机器账号抓发自己的微博。
3、似乎现在还有人在继续以机器的形式转发。
我们通过分析,发现了几个重点作恶的帐号,这些帐号虽然是正常人在维护,但是他们使用大量水军帐号转发自己的微博,严重干扰了微博的正常秩序,已经对这些帐号进行永久封禁。目前还残存的机器帐号我们正在进行处理。
4、对于这样的情况,微博方面是否有什么好的处理方式?
对于这种情况,微博已经采取了一系列的反垃圾措施,从技术和产品机制上进行优化,最大限度的防范机器帐号行为。
5、新浪微博官方对这些水军、机器的态度是怎样的?
新浪微博坚决打击这种水军、机器帐号,一经发现进行永久封号处理。同时,对于购买或雇佣水军的帐号进行相应的惩罚措施。
6、之前发给我的这个数据,是截止到什么时间的?
截止10月8日上午10点半左右
在昨天报道了这次事件之后,我们很快联系了
乐荐网络创始人
戴虎宁,让他帮忙分析一下这次千万次转发数据中的水分(当时没想到新浪微博官方会回应)。经过一晚上挖掘了240多万条数据之后,戴虎宁也得出了一些
结论:
@豪门吉品鲍府 豪门1300万转发分析新鲜出炉!目前分析了240万次转发,参与人数4万多人 动态增长中请移步:
http://t.cn/aFvKq8 已知规律:1. 每个僵尸转发次数集中在30次左右,2. 粉丝数0关注20以下的僵尸最多,3. 次抛型僵尸,微博数集中在30-40 4. 僵尸喜欢江苏和四川省 @36氪 @truant @techfans
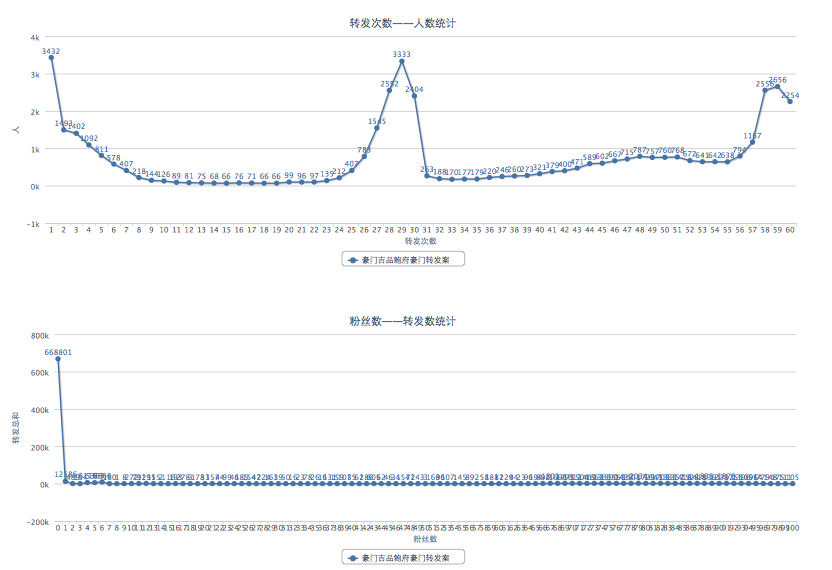
现在我们也可以得出结论:这次千万次转发的豪门惨案,很有可能是@豪门吉品鲍府 的一次炒作行为,根据新浪微博回复的邮件,也不排除有一部分用户为了得奖主动去购买或制造机器帐户抓发自己的微博。新浪本身没有参与这次事件,但直到转发数过了千万他们才做出反应,速度实在有点慢。这次事件之后,那些专门做微博营销的公司在新浪微博上将更难做。这次千万级别的转发数,不但前无古人,恐怕也后无来者了。
目前这条被转发千万次的微博已经经过新浪微博官方的处理,只剩下9000多次的转发(
链接)。













