Kyligence获红点数百万美元天使轮投资,构建基于Hadoop的数据仓库及OLAP产品
大数据公司Kyligence跬智科技日前宣布获得了数百万美元的天使轮投资,投资方为红点资本。
Kyligence于2016年初成立,总部位于上海。致力于为用户提供基于Apache Kylin的智能分析平台及产品,以及企业级商业分析解决方案。
创始团队成员来自eBay,IBM,微软,摩根斯坦利,SMG等著名互联网及数据公司,包括多位Apache Kylin™的核心贡献者,并活跃于各个开源社区,Apache Kylin是第一个由中国团队完整贡献到ASF(Apache 软件基金会)的顶级项目。
对此,36氪采访了Kyligence联合创始人兼CEO韩卿 (Luke Han) :
Kyligence 的诞生解决了哪些痛点?
随着Hadoop为代表的大数据技术的普及,越来越多的数据被收集、存储起来,并进一步进行各种处理以满足不同的业务分析需求。业界的实践证明,分布式大数据平台可以有效的进行各种批量处理、数据加工甚至挖掘等,为“机器”使用和处理大量数据带来了前所未有的便利和能力。
但大数据的飞速发展并没有为传统的数据分析师带来更多的好处。其原因在于Hadoop等大数据平台能很好的满足批量数据处理需求但缺很难让“人”以“交互式”的方式在超大规模数据集上进行各种不同维度的快速分析,特别是Hive等最终将SQL查询翻译成MapReduce的方式无法让用户在秒级时间内获得他们所需要的结果,而且很多分析师不得不使用Shell终端等方式访问和运行相关脚本,远远超越了对一个分析师、BI人员的要求。
同时,由于处理时间和方式的差异,很难在短时间内获得分析结果,从而加大了企业内大数据分析平台及应用在推行上的难度。
此外,高端大规模并行处理 (MPP)数据仓库往往都以软硬一体机的形式提供,除了价格昂贵,没有开源以外,将大量数据从Hadoop等平台再次拷贝到这类平台上也带来了极大的工作量和额外存储成本,而业界越来越流行将数据保存在一个平台上,而将“计算”送往“数据”,以降低总体拥有成本。
基于此,Apache Kylin被开发出来以解决超大规模数据集上秒级甚至亚秒级的挑战,提供分析人员以交互式的方式访问和分析的能力,解决了大数据分析应用落地的实际难题。
Apache Kylin内数据流的形式变化
大部分情况下,作为为业务人员或分析人员所用的数据往往以结构化形式呈现,在存储上,特别是在Hadoop平台上以Hive形式暴露,从而提供传统RDBMs的接口以使分析人员通过SQL,分析人员通用语言,进行访问和分析。
在Apache Kylin内,数据将首先从Hive进行读取,此时,数据以行列式的方式被读入,之后数据会在不同的Map Reduce任务间进行各种计算,从而将最终结果转换为Key-Value组合,即Key为维度组合,Value为各种指标值,最后存放于HBase中。
在用户提交标准SQL查询到Kylin服务器后,该查询会被解析并转换为HBase的标准API访问,获得相关数据后,进一步组织成标准的SQL数据结果集返回给调用者,在这个过程中,没有任何的Hive读取,没有任何的MapReduce读取,这也是Kylin查询性能非常快速的原因之一。
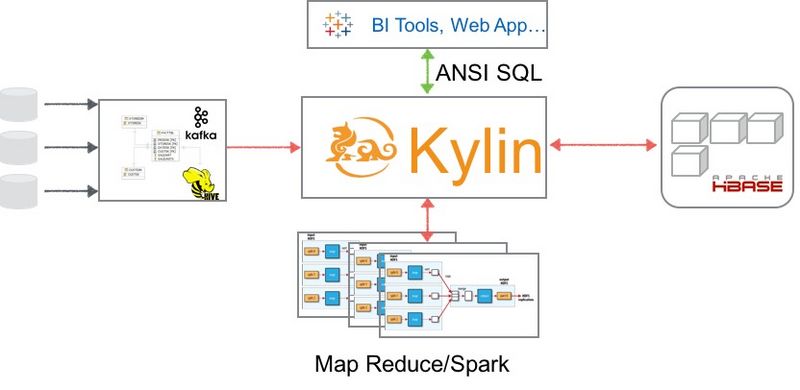
Kyligence与下层Hadoop、上层BI展现的区别,各自在性能与并发上有什么瓶颈?
Kyligence的目标是构建基于Hadoop的数据仓库及OLAP产品,因此,Hadoop是Kyligence的底层存储和运算框架,细节上,Hive、SparkSQL、Kafka等是Kyligence的数据源,Map Reduce,Spark等是Kyligence的运算引擎,而HBase等则是Kyligence的存储层。
通过Kylin的预先计算及流式计算,将相应的数据依据业务需求构建数据集市并予以存储,从而在大量分析请求到来的时候无需访问原始数据源,无需每次调用Map Reduce等处理任务,直接将匹配的数据结果提供给前端工具使用,从而为超大规模数据集提供极速的访问能力。可以从eBay,网易等公开的资料和文章上看到,相关的性能大大快于传统的数据仓库产品。相关生产环境上的实例证明,Kylin在千亿规模数据(单一数据表)上可以做到95%的查询在1秒内返回,目前很少有其它技术可以在此规模上达到类似的性能。
对于前端展现层,通过标准的ODBC及JDBC驱动,REST API等,Kyligence可以与各种BI工具,可视化工具等无缝整合,以标准的SQL为用户提供分析能力。
以往OLAP应用在并发上表现并不理想,由于需要大量的读取底层数据,或者扫描大量的数据表,或者在网络间需要巨量数据交换,在几十的并发压力下已经做到极限。而得益于Kylin的预先计算及无状态服务器等特性,Kyligence所提供的产品可以轻松做到三四百以上的并发度,在京东等用户案例中可以甚至可以看到已经通过Kylin提供对公网的服务,这是其他OLAP产品所无法提供的。
Kyligence做这个中间层有什么必要?
Kyligence所提供的OLAP及数据集市层,填补了大数据平台与分析人员之前的空白,如Apache软件基金会在Kylin毕业成为顶级项目的官方新闻中评价的:“作为一个领先的基于Hadoop的OLAP解决方案,Apache Kylin填补了大数据与人使用之间的空白,使分析人员,最终用户,开发者和数据爱好者能够在大规模数据集上进行亚秒级延迟的交互式分析。
基于这些能力,Apache Kylin将商业智能(BI)带回Apache Hadoop以释放出大数据的价值”。由下图可见,Kylin很好的在大数据平台上为业务人员,分析人员提供一层重要的分析层,将各种业务分析模型通过Cube的形式进行组织和整理,使得他们能够通过熟悉的各种分析工具直接获得分析结果。
此外,Apache Kylin也将传统的读写分离架构带入到了大数据分析领域中,在今天,上千台的集群规模已经很容易实现,而其上的任务可以跑到千万个上亿个。而超大集群往往同时承担着各种不同的业务应用和分析需求,从而使得集群极其繁忙更有甚者资源调度不均从而导致处理性能及稳定性下降等。通过Kylin的预计算能力,可以将分析需求所需要的数据经聚合运算后存储于独立的节点或集群,上层展现层及分析需求都迁移至该集群,从而将分析需求与运算集群解藕,从而达到大数据分析平台的读写分离,使得故障隔离和高可用性成为可能。
关于开源Apache Kylin及商业版本的区别
Kyligence成立后将使得核心开发者更加专注在Apache Kylin的开发和迭代上,基于即有的路线图和来自社区的需求进一步演进以提供更好的架构和性能。同时,Kyligence公司将为有需求的客户通过其企业级产品Kyligence Analytics Platform(KAP)提供商业支持以及企业级功能,KAP将基于最新的Apache Kylin发布版本并完全兼容,为各种不同的Hadoop发行版提供更加全面的测试和质量保证,并增加例如安全加密,高可用性,自动化及管理等企业级特性。
据悉,Apache Kylin已经在国内国际多个公司被采用作为大数据分析平台的关键组成部分,包括eBay、Expedia、Exponential、百度、京东、美团、明略数据、网易、中国移动、唯品会等。













