Google 发布新的机器翻译系统,但它真的能抢笔译人员的饭碗吗?
今年的9月27日是Google翻译推出10周年的日子,这一天Google发布了人工神经网络机器翻译系统(GNMT),以此来为 Google 翻译庆生,并表示 GNMT 的平均出错率比之前的系统降低了 60%。Google称,与之前采用基于短语的机器翻译算法(PBMT)相比,GNMT的复杂性提高了一步,翻译质量更高,在多个主要语言对的翻译中实现了翻译误差降低55%-85% 以上。GNMT算是目前最新也是最有效地将机器学习用于翻译的系统。那PBMT和GNMT都是怎么回事呢?机器翻译是怎么走到目前这一步的呢?
最简单的翻译是将一个句子逐字从源语言转换成目标语言。显然,只要手上有对照字典就能够完成这项任务。这能够把个别关键词翻译过来,但这种做法的效果基本上都是惨不忍睹,比如对于口头语言的语气语调等的把握就非常差了,更不用说不同的语言本身还有很多微妙玄机。
于是为了提高翻译质量,人们自然想到了要对文字进行解构。文章由段落组成,段落由句子组成,句子由短语和字组成。尤其是短语用法基本固定,灵活性并没有单字或词那么强,无论在怎样的上下文当中语义都相对固定,如果能针对短语进行翻译,可以提升翻译的品质,这就是所谓的基于短语的机器翻译(PBMT),10年前推出的Google翻译正是以这种算法为核心的。PBMT系统翻译的基本单位是短语,不过在翻译过程中它并不是孤立地逐词翻译, 而是考虑了连续的多个词,通过对照庞大的双语语料库来提取翻译。这种基于短语的方案可以比较容易地对局部上下文关系进行处理,相对于逐字翻译在质量上有了较大提高。
但是,正因为PBMT是基于局部的上下文依赖关系,所以在遇到较长的句子或短语时它的处理就容易出现问题了。此外,由于PBMT完全是依靠连续短语的统计信息,忽略了语言的句法特征,因此不能够充分利用语料库所包含的知识,这就限制了翻译质量的更上一层楼。
从这里我们可以看出,了解深层次的上下文关系是关键。顺着这种思路,我们很容易就能想到如何进一步获得更好的上下文关系——从短语扩大到句子,也就是直接从一个句子映射到目标语言句子,因为这种映射需要深度学习的帮助,所以又被称为基于人工神经网络的机器翻译(NMT,Neural Machine Translation)。几年前,Google利用长短时记忆(LSTM,Long Short-Term Memory)循环神经网络(RNN,Recurrent Neural Network)支持下的NMT改进了自己的翻译效果。它可以将任意长度的句子转化成向量,在网络中层层传递,转化为计算机可以“理解”的表示形式,再经过多层复杂的传导运算,生成另一种语言的译文,也就是说翻译深化到了语义理解的层面。
但是NMT系统也有问题。那就是这种神经网络的训练和翻译推理的计算成本非常高,当然这也难怪,因为翻译的复杂性提高后势必对处理也提出了更高的要求。不过NMT还有一个劣势,那就是对于罕见词大多数 NMT 系统都难以应对。这两个问题一个会影响到翻译速度,另一个则影响到准确度。所以导致了NMT比较难以进行大规模的实际应用,因为这两个特性都非常关键。想象看,如果Google翻译5、6秒都出不来的话,还有什么用户使用呢。
为此Google的Brain团队开始着手考虑解决NMT的实用性问题。他们推出的Google Neural Machine Translation(GNMT,Google基于人工神经网络的机器翻译)是一个应用于生产环境的机器翻译系统,它使用了一个深度的长短时记忆神经网络,该网络含有8层的编码器和解码器,解码器网络和编码器网络之间同时利用了残差(residual)连接和注意力(attention)连接。为了缩短训练时间,Google团队对神经网络的并行机制进行了改进,让attention机制将解码器的底层与编码器顶层进行连接来加速训练,并且通过降低推理计算精度来加速最终的翻译速度。对于罕见词的处理问题,团队将罕见词分割成常见词子集,这种做好较好地在字符限定模型的灵活性以及单词限定模型的效率之间进行了平衡,最终改善了整套系统的精确度。为了让译文考虑到尽可能多的源文词汇,其用于搜索目标语言句子空间的定向搜索算法采用了长度规格化过程,并且利用了覆盖惩罚来鼓励生成尽可能多覆盖源文词汇的输出句子。通过上述努力,与Google在用的PBMT翻译系统相比,其翻译的平均错误率已经下降了60%。
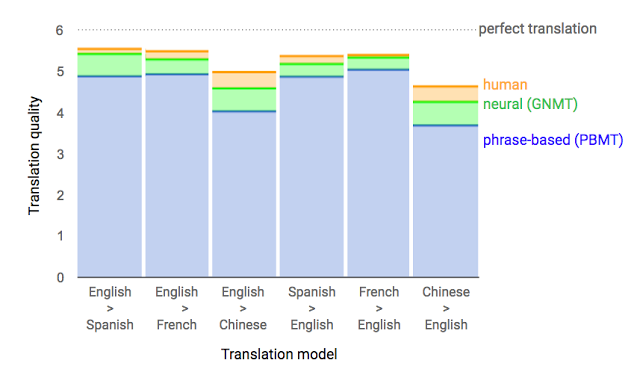
下图是Google提供的,由人类评估者对不同语对之间人类翻译、GNMT翻译以及PBMT翻译的质量对比情况。其中0为最低,即完全的牛头不对马嘴,而6则是完美翻译(从图中可以看出目前并不存在,哪怕是最高水平的人类翻译)。综合来看,GNMT已经拉开了与PBMT的距离,跟人类翻译的水平比较接近了。尤其是英法互译方面,几乎已经跟人类水平无异。而中英、英中互译在不同语对之间的翻译水平是最低的,我想这与中文的语系跟英文不同以及汉语的复杂性太高有着很大的关系。
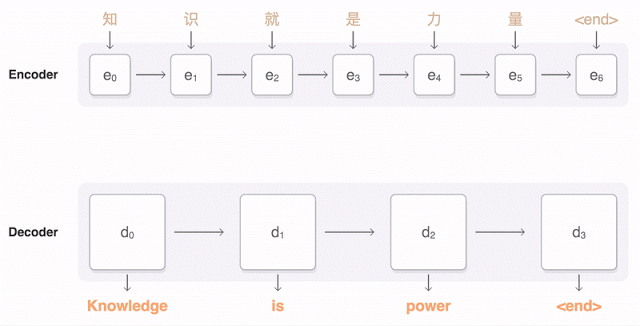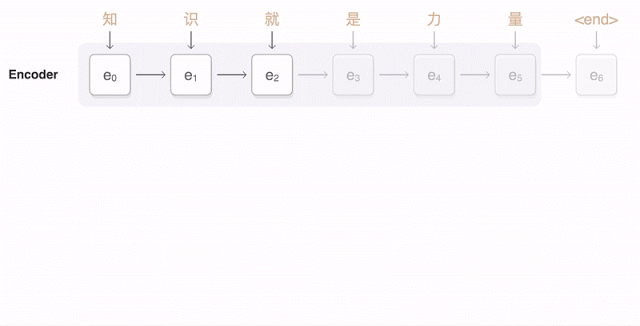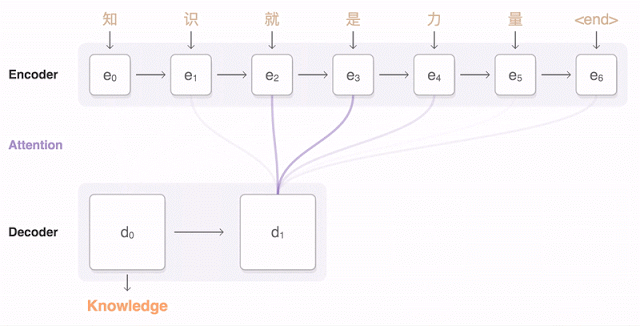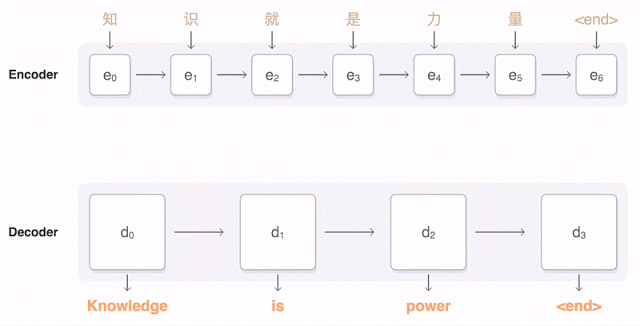
但是在短句的翻译方面,由于Attention机制的引入,使得解码器端可以更多地关注源语言端的部分词,从而避免了原来编码器—解码器模型固定维度的上下文向量带来的精确度不高的问题。比如,下面这幅动图就形象展示了GNMT将汉语的一句话翻译成英语的过程。首先,网络将汉语的词编码为向量表,每一个向量都代表着迄今为止读到的所有词的意思。一旦整个句子读完,解码器就开始工作,逐字来开始生成英文句子。但是这种解码(翻译)并不是简单的逐字翻译,而是会注意看目标英文词与源中文词的匹配程度,从中选取匹配程度最高的英文单词输出(所谓匹配程度也就是对编码中文的上下文向量赋予一个关注度权重,图中编解码器之间的蓝色链接透明度代表了解码器对某个中文词的关注程度,透明度越高代表关注度越高)。从这个翻译结果来看,效果还是很令人满意的。
Google官方博客表示,公司已经将这套GNMT应用于难度“臭名卓著”的语言翻译对:中译英上面。目前Web版和移动版的Google翻译中译英已经100%采用GNMT,每天大概要处理1800万次翻译。他们使用的机器学习框架是Google自家研发目前已经开源的TensorFlow,并且硬件上采用了自己研发的专用人工智能处理器TPU(Tensor Processing Units)。Google表示,未来几个月将会把GNMT推向更多的语言翻译对上。
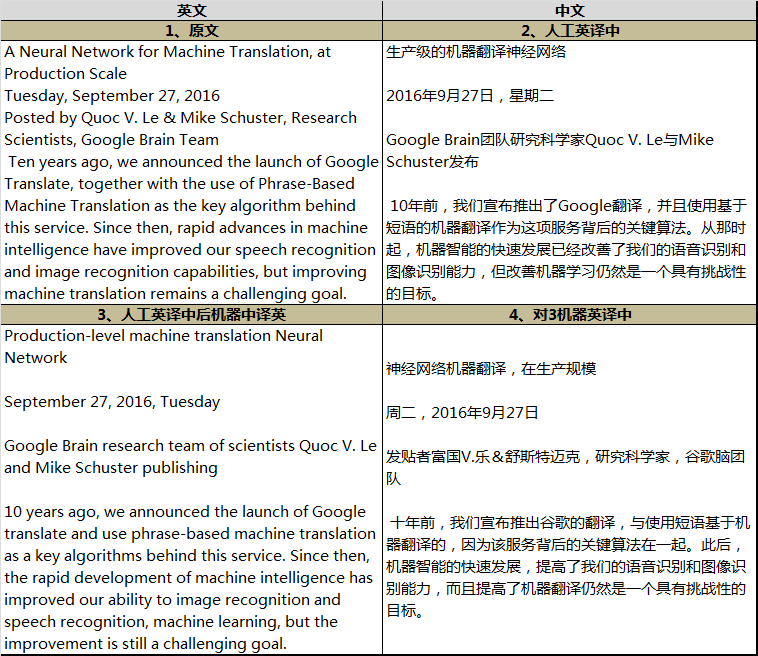
作为试验,我试着把官方博客的一段话译成了中文(表中的2),然后再用Google翻译把这段中文译成英文(表中的3)。从对比来看,除了个别语法方面的问题以外,英文的还原度还是挺高的,起码意思并没有太大的偏差。但是再把3这段英文机器翻译为中文(表中的4)后,效果就差很多了,尤其是基本的意思并没有表达出来。
就像Google所说那样,机器翻译的道路还任重道远。关键是这种翻译在考虑上下文语境方面还非常不足,目前也仅考虑到一个句子中的关系而已,更不用说段落、章节甚至外部引用这些复杂关系了。而目前的机器翻译纯粹是走算法和统计的路线,跟真正的语言学并没有什么关系,这种路线在改善翻译质量方面究竟能走多远呢?此外,Google在硬件上使用了专门定制的TPU来加速机器学习方面的运算。不过一旦AI模型改变,TPU就要重新定制生产,这对于他们的实用化可能也会产生不小的影响(相比之下,微软采用FPGA的办法灵活性似乎更强一些)。所有这些问题都说明,尽管机器翻译已经取得了不小进展,但未来的挑战更大。AI和自然语言处理界能否取得更大突破呢?我们拭目以待吧。













