在手机端驱动虚拟形象,FaceUnity并不满足动画应用未来想发展VR应用
前段时间火爆社交网络的Faceu可以利用手机摄像头对人脸进行进行追踪和识别,叠加动态贴纸或是美颜滤镜。而初创公司FaceUnity已经不满足单单在人脸上叠加道具或是滤镜,它们旨在用简单的摄像头来实时追踪和识别人脸,然后驱动虚拟形象。
之前36氪报道过被苹果收购的面部追踪和动画公司Faceshift就是通过捕捉面部表情并实时映射到角色中来驱动虚拟形象。但是Faceshift需要用到深度摄像头,并且无法应用于移动端。FaceUnity 则解决了这些问题。Faceunity是一家以3D人脸运动捕捉和动画驱动为核心技术的初创公司。目前已经推出 2 款产品,一款是用于移动端平台表情捕捉的SDK开发包,可以集成到app里,实现虚拟形象的驱动。另一款则是为 MAYA/3DMAX 等 3D 制作工具开发的人脸表情动作制作插件。

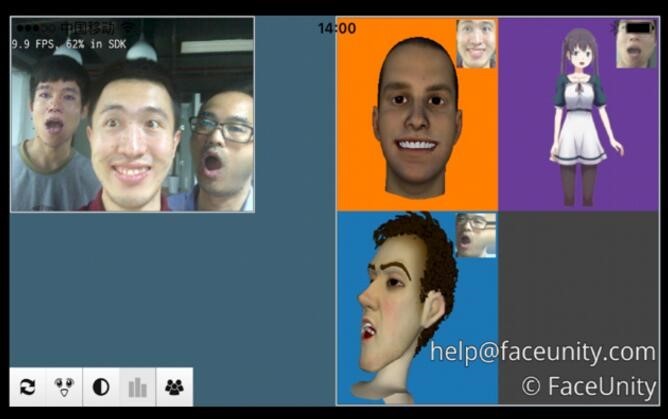
市场经理刘世军向36氪介绍到FaceUnity可以使用普通摄像头进行人脸的面部捕捉,并且精度可以达到和深度摄像头一样。比如像电影《阿凡达》里虚拟形象的制作都是非常耗时耗力的,如果使用了FaceUnity的方案就可以利用很简单的设备去高效率的完成电影拍摄。此外,FaceUnity打破了只能使用在PC端的束缚,可以应用于移动端。也就是说搭载了FaceUnity模块的手机使用手机摄像头就可以实时进行人脸追踪和虚拟形象的驱动。而且Faceshift在一个画面只能驱动一个人脸,而FaceUnity可以同时驱动多个人脸,这也为其应用提供了更多可能性。
刘世军给36氪介绍了FaceUnity方案的基本原理,通过单个视频实时获取人脸动画数据,这些数据会帮助建立一系列基本表情,用户的每一个实时表情都用这些基本表情进行合成,从而就可以实现虚拟化身的驱动。
此外,刘世军也说道国内也有几家公司在做人脸技术,比如Face++,但是它们专注于识别人脸,而人脸识别的精度则需要靠大数据的积累。而FaceUnity与它们的区别在于FaceUnity专注于人脸跟踪、驱动和动画,即识别人脸后去驱动一个虚拟的形象。
现阶段FaceUnity的主要客户是来自游戏和直播行业,因为很多游戏里涉及到了人脸表情部分,传统方式对表情做渲染比较费时费力。而直播行业的客户一直想把虚拟形象用在直播中,比如说人脸贴纸和道具,最早使用了表情捕捉技术的有花椒直播,之后映客直播也推出了类似功能。但是这项技术对于做直播的门槛很高,即使做出来效果也不一定好。而据刘世军的介绍使用FaceUnity的技术方案,直播平台客户可以在3-5天时间就完成类似花椒的人脸道具功能。
此外FaceUnity也积极进行了其他场景的应用尝试,未来希望可以在VR领域有更多应用。在VR领域比如虚拟社交中,可以实时感受到对方的表情是非常关键的。之前Facebook发布的VR产品演进的方向是在设备里放置传感器和摄像头来捕捉人脸,FaceUnity现在也在和国内一些做VR的硬件厂商进行合作,通过搭载在头显设备上进行面部表情实时追踪。刘世军表示产品现在正在调试阶段,比如如何放置设备,怎样的精度是可以接受的,可以进行面部表情实时追踪的VR设备应该很快就能做出来。

刘世军表示FaceUnity的业务重点在SDK,因为SDK的可扩展性更强,行业应用更多。现阶段公司盈利主要靠SDK技术授权。刘世军表示短期内动画会成为公司的盈利的主要领域,而在长远上公司更希望VR领域可以成为盈利重点。
刘世军介绍到FaceUnity面部追踪和识别的演示应用FU Live已经在Apple Store上线,36氪也在第一时间进行了体验。FU Live有两大功能——人脸的实时追踪和识别、实时画面的滤镜美颜。人脸的实时追踪和识别功能中除了传统的在人脸上叠加动态3D道具功能,还可以选择实时驱动一个虚拟形象。驱动的虚拟形象的面部表情基本可以和用户的面部表情同步,只是表情变化幅度会小一些。并且当镜头检测到面部有遮挡或只检测到人脸的侧面,则无法进行面部识别和表情追踪。

FaceUnity 成立于今年 3 月份,刚完成一轮pre-A的融资。现阶段公司重点放在了核心技术研发方面。FaceUnity团队成员大多毕业于清华大学和浙江大学,核心成员曾任职于微软公司,具有多年从事VR技术和应用研发的工作经验。













