僵尸机器变大白,翼开科技想做情感计算领域的OpenAI
现在绝大多数的情绪识别手段都是基于单一参数,即表情或语音数据进行深度学习的,比如以色列公司Beyond Verbal是通过语速、语调、停顿等判断情绪,美国公司Affectiva和Emotient是通过对面部动作编码和分析来判断表情的。
北京的情感计算初创公司翼开科技希望引入其他对情绪判断更有利的参数,进行多模态拟合,提高情绪识别的精准度。现阶段其Emokit海妖情感计算引擎使用表情、语音、心率、笔迹四个参数可以识别12种正面情绪和12种负面情绪,覆盖了100多个标注关键词。翼开科技CEO魏清晨告诉36氪,人类的表情和语音数据容易采集,但是也容易被伪装的,而心率、皮电等这类体征是由中枢神经控制的,人类很难伪装,因此这些参数在情绪判断中所占的权重更多,但这些参数并不易于采集。翼开科技自2011年开始开发模型算法,这期间积累了大量的标注过的训练数据,相比于未来进入这个领域的其他竞争者,魏清晨认为翼开科技在关键的数据量上有明显优势。
魏清晨表示这四个参数可以单独使用来进行情绪识别,使用表情对情绪进行判断的精度可以达到90%以上,使用语音、心率、笔迹等参数进行识别的精度约为85%。而翼开科技也在针对这四种参数在不断地进行识别优化。针对表情识别的优化有两种路径,一是通过采集数据再请人做标注反哺现有的模型,二是通过不同角度不同光线的人的情绪照片来优化模型。针对语音、心率、笔记的识别优化,一是通过纵向学习,即不断观测某一用户的体征特征同时扩大用户数量来优化识别的精准度,二是通过无监督学习,即对用户的体征特性进行情绪判断,然后匹配相应的服务或内容,在用户体验服务和内容的同时继续观测体征特性,然后看用户情绪是否因为匹配的内容得以优化。
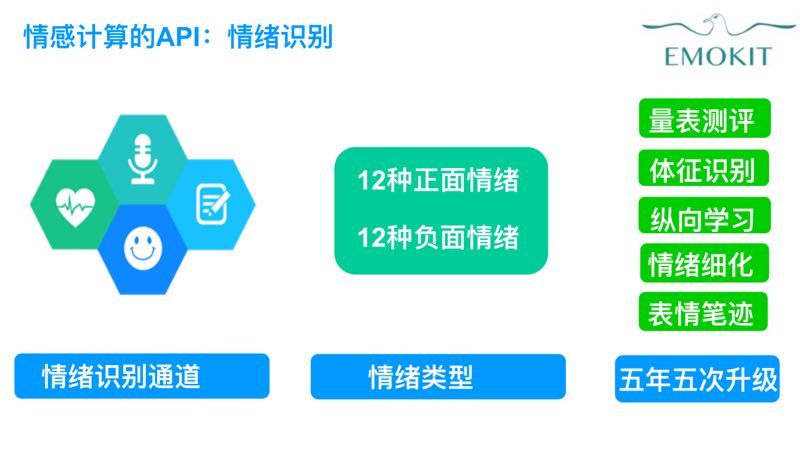
魏清晨告诉36氪他们下一步要对多种参数进行动模态拟合,以进一步提高情绪判断的精度,这主要有两种实现路径,一是通过摸索的手段,对参数进行标注然后进行深度学习。比如说电影的某个片段,90%的人对其标注是开心,然后对表情、语音、动作等进行拆分。另一种路径是基于心理学基础上,通过对情绪的认知,去完成情绪标签的梳理。这部分的研发刚刚启动,已经有了初步的技术积累。
翼开科技主要面向B端和D端的应用市场,现阶段EmoKit有三种应用形态,一是免费开放的SDK,目前的合作案例有科大讯飞、环信等平台,SDK的用户数量已有2000万,并且以几十万每天的速度增长。二是作为免费硬件OS中的必备模块应用在智能硬件、智能车载、智能家居等领域,合作案例有海尔、英特尔、Androidwear等。三是模拟人类的情感并将应用于人工智能,目前的合作方有图灵机器人、灵聚智能引擎等。此外也针对某些特定用户,如军队、幼儿园、呼叫中心等开发定制的方案打包销售。
翼开科技去年完成了第一轮600万元的融资,投资方为星火金融。现在正在寻求4000万元的融资,资金将用于扩充团队,以及搭建人工情感的云计算中心和云服务平台,最终成为人工智能的重要基础设施之一。
EmoKit的核心团队成员拥有脑神经认知、机器学习、大数据、心理学等多种学科背景,其中首席科学家杨滢毕业于美国CMU大学,脑神经认知博士后,杜鹏飞毕业于北京航空航天大学,大数据硕士。翼开科技同时先后与中科院心理所、清华大学心理学系、美国CMU大学语言技术研究所建立了学术合作关系。













