超越Hadoop和Spark, 「Data Thinker」全面提高大数据存储和处理效率
根据国际数据公司(IDC)的监测数据显示,2018年全球大数据储量达到33.0ZB(1ZB≈1万亿GB),同比增长52.8%。从大数据储量分布来看,中国大数据储量占全球的23%,居世界第一,美国为21%,EMEA(欧洲、中东、非洲)为30%。
那么,如何处理呈爆炸式增长的大数据?目前国内外覆盖范围最广的大数据处理系统为美国的Hadoop和Spark。
Hadoop是第一代大数据技术,也是主流的大数据生态,典型用户包括中国工商银行、百度等。它的核心是HDPS(分布式文件系统)和MapReduce(分布式计算框架)。Hadoop解决了用户在一定时间内数据的存储和处理问题。但随着数据的日益增多,MapReduce易出现数据迟滞、迭代式数据处理性能较差等问题。当然,在随后的发展中,Hadoop生态圈也出现其他项目以适应市场需求,如Pig(数据流处理)、Mahout(数据挖掘库)等。但这些产品由不同团队、组织开发,纷繁复杂、学习难度大,维护成本较高。
Spark是基于内存的分布式计算引擎,也是近两年较为火热的第二代大数据技术的代表。它在语言层面把数据作为分布式的对象存储起来,利用内存大数据计算,从而解决第一代MapReduce计算数据的迟滞等问题。目前越来越多的企业开始使用Spark,如Uber、Netflix等。简单来说,Hadoop是面向磁盘的,Spark是面向内存的,后者决定了它的数据处理效率更快,更加适合于数据排序、报表等具体应用。
针对大数据处理效率不高这一痛点,我国也有企业进行相关软件的开发。深圳湖图塔信息技术有限公司(以下简称“湖图塔”)自主研发了大数据基础软件——Data Thinker(下称“D-thinker”),采用内存大数据计算方法,实质上属于第二代的分布式大数据处理系统。
D-thinker不依靠开源软件,用新型分布式指令集Esperanto整合众多计算机的CPU、内存及硬盘资源,通过基础软件融合形成数据空间高达16EB (1EB≈10亿GB)的“大计算机”,可实现所有已知大数据算法和应用。
相较于Spark,D-thinker基于自主研发的BigMessage高效数据模型,使其性能较Spark高1.6-5倍,较Hadoop高2-70倍。“举例来说,一个人的全部基因数据,大约为200GB。以往需要2天去处理,就算Spark也要5到6小时才能完成。但通过Data Thinker分布式处理,只需45分钟,提高了几十倍的效率。D-thinker是目前全球性能最好、速度最快的分布式大数据引擎”,「湖图塔」创始人顾磷介绍道。
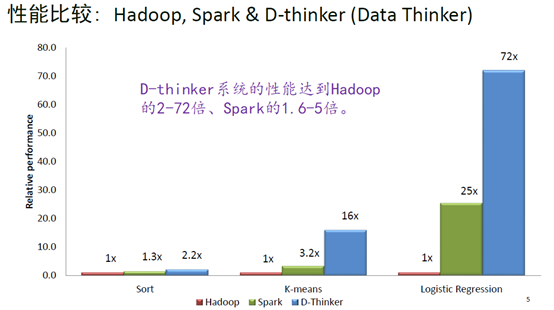
D-thinker与Hadoop、Spark的性能比较 (来源:湖图塔)
D-thinker采用混合云的商业模式。首先通过出售或租赁方式,在用户的工作地点建立模块化和私有化的数据系统;其次利用云平台协助用户管理大量数据。落地场景主要集中在生物医疗、政府、金融三个领域,其中包括基因组计算、社会管理、金融科技等具体应用。目前,「湖图塔」已拥有国家癌症中心、海普洛斯、中南大学湘雅医院、宁波市公安局北仑分局等40多家合作伙伴。
谈及未来的走向,顾磷认为,目前大数据应用分为OLTP(On-Line Transaction Processing,联机事务处理过程)和OLAP(On-Line Analytical Processing,联机分析处理)两类,后者是近年大数据应用较为繁荣的领域,D-thinker就是其中之一。但根据如今的发展趋势,二者的融合势在必行。“我认为OLAP 和 OLTP的融合在最近一两年就会有进展。所以,Data Thinker也往这方面发展,在做相关的数据库。使数据不但能够进行大量分析,还能进行事务式的业务操作。”
据悉,「湖图塔」团队规模约为20人。创始人顾磷为美国弗吉尼亚大学计算机博士,先后任职于微软、北大方正、雅虎、谷歌等大型企业,并曾在香港科技大学任职。其他核心成员也均有相关软件开发经验。













