机器学习测试笔记(19)——聚类
编者按:本文来自微信公众号“软件测试培训”(ID:iTestTrain),作者:顾翔,36氪经授权发布。
顾老师新书《全栈软件测试工程师宝典》
https://item.m.jd.com/product/10023427978355.html
以前两本书的网上购买地址:
《软件测试技术实战设计、工具及管理》:
https://item.jd.com/34295655089.html
《基于Django的电子商务网站》:
https://item.jd.com/12082665.html
1.概念
在有监督学习中分组叫做分类。它是有标签的,比如苹果可以分为:国光苹果、红香蕉苹果、阿克苏苹果…,而在无监督学习中分组叫做聚类,他是没有标签的,它把相同的元素分为一组。在聚类中,分类后的每一组叫做簇。
2.K均值聚类
2.1 概念
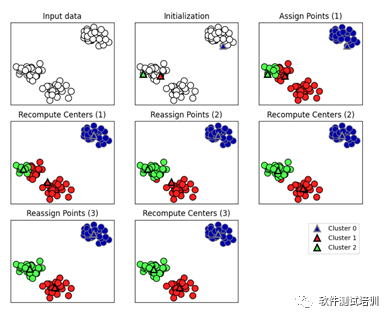
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。(K均值聚类是不是有点像K邻近算法?)。
k-means算法基本步骤:
从数据中选择k个对象作为初始聚类中心;
计算每个聚类对象到聚类中心的距离来划分;
再次计算每个聚类中心
计算标准测度函数,直到到达最大迭代次数,则停止,否则,继续操作。
我们可以简单通过下面代码了解K均值算法的过程。
# K均值聚类def agglomerative_algorithm(): mglearn.plots.plot_kmeans_algorithm() plt.show()
2.2 程序
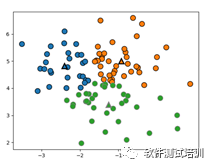
通过sklearn.cluster.KMeans算法实现。我们通过下面代码来看一下K均值聚类的散点图分布
#K均值算法,Sklern KMeans算法from sklearn.datasets import make_blobsfrom sklearn.cluster import KMeansimport mglearn #pip3 install mglearnimport matplotlib.pyplot as pltimport numpy as np
def my_KMeans(): blobs = make_blobs(random_state=1,centers=1) X = blobs[0] y = blobs[1]#设置簇个数为3 Kmeans = KMeans(n_clusters=3) Kmeans.fit(X) print("训练集数据集分配簇标签为:\n{}".format(Kmeans.labels_)) print("对训练集数据集预测结果为:",Kmeans.predict(X))#画出聚类后的数据集图像 mglearn.discrete_scatter(X[:,0], X[:,1],Kmeans.labels_,markers='o') mglearn.discrete_scatter(Kmeans.cluster_centers_[:,0], Kmeans.cluster_centers_[:,1],[0,1,2],markers='^',markeredgewidth=2) plt.show()
输出
训练集数据集分配簇标签为:[2 2 0 1 1 1 2 2 0 1 2 1 2 0 2 1 1 2 0 0 1 0 2 2 2 2 1 2 2 2 0 0 2 2 1 0 1 0 2 0 1 2 0 0 1 1 1 2 0 2 0 2 1 0 1 1 0 1 1 2 1 0 1 2 0 1 0 0 2 1 1 2 1 1 1 2 1 2 2 0 1 0 1 1 0 2 1 2 0 0 1 2 0 0 1 1 2 1 1 2]对训练集数据集预测结果为:[2 2 0 1 1 1 2 2 0 1 2 1 2 0 2 1 1 2 0 0 1 0 2 2 2 2 1 2 2 2 0 0 2 2 1 0 1 0 2 0 1 2 0 0 1 1 1 2 0 2 0 2 1 0 1 1 0 1 1 2 1 0 1 2 0 1 0 0 2 1 1 2 1 1 1 2 1 2 2 0 1 0 1 1 0 2 1 2 0 0 1 2 0 0 1 1 2 1 1 2]
标签是一致的。
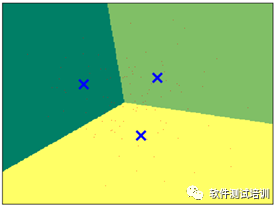
更详细些,我们把边界按照传统的方法画出来,蓝×表示数字中心。
X_blobs = blobs[0] X_min,X_max = X_blobs[:,0].min()-0.5,X_blobs[:,0].max()+0.5 y_min,y_max = X_blobs[:,1].min()-0.5,X_blobs[:,1].max()+0.5 xx, yy = np.meshgrid(np.arange(X_min, X_max, .02),np.arange(y_min, y_max, .02)) Z = Kmeans.predict(np.c_[xx.ravel(),yy.ravel()]) Z = Z.reshape(xx.shape) plt.figure(1)plt.imshow(Z,interpolation='nearest',extent=(xx.min(),xx.max(),yy.min(),yy.max()),cmap=plt.cm.summer,aspect='auto',origin='lower') plt.plot(X_blobs[:,0],X_blobs[:,1],'r,',markersize=5)#用蓝色×代表聚类的中心 centroids = Kmeans.cluster_centers_plt.scatter(centroids[:,0],centroids[:,1],marker='x',s=150,linewidths=3,color='b',zorder=10) plt.xlim(X_min,X_max) plt.ylim(y_min,y_max) plt.xticks(()) plt.yticks(()) plt.show()
其实我们可以用mglearn类更简单地画出类似效果。

我们用K均值聚类处理iris数据。
from sklearn import datasetsdef KMeans_for_iris(): X,y = datasets.load_iris().data,datasets.load_iris().target Kmeans = KMeans(n_clusters=3) Kmeans.fit(X) result = Kmeans.fit_predict(X) print("iris 原始数据集分配簇标签为:\n{}".format(y)) print("iris Kmeans训练簇标签为:\n{}".format(result))
输出
iris 原始数据集分配簇标签为:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]iris Kmeans训练簇标签为:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 1 1 1 1 2 1 1 1 1 1 1 2 2 1 1 1 1 2 1 2 1 2 1 1 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1 1 1 2 1 1 2]
对0分得比较精确,1和2都有偏差。
3 凝聚聚类
3.1 概念
凝聚聚类(agglomerative clustering)指的是许多基于相同原则构建的聚类算法,这一原则是:算法首先声明每个点是自己的簇,然后合并两个最相似的簇,直到满足某种停止准则为止。
我们可以通过以下代码来了解一下凝聚聚类算法。
#凝聚算法from scipy.cluster.hierarchy import dendrogram,ward def agglomerative_algorithm(): mglearn.plots.plot_agglomerative_algorithm() plt.show() blobs = make_blobs(random_state=1,centers=1) x_blobs = blobs[0]#使用连线方式进行可视化 linkage =ward(x_blobs) dendrogram(linkage) ax = plt.gca() # gca:Get Current Axes#设定横纵轴标签 plt.xlabel("sample index") plt.ylabel("Cluster distance") plt.show()
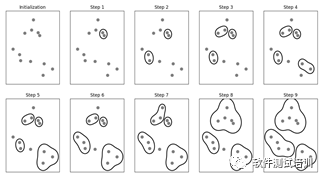
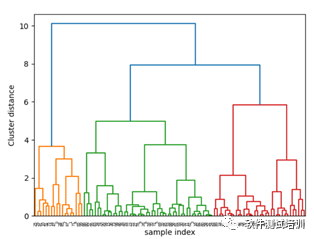
注意:度量相似值,Sklearn有四种选项
linkage :{"ward", "complete", "average","single"}, optional (默认="ward")
ward链接:默认选项,挑选两个簇来合并,是的所有簇中的方差增加最小。这通常会得到大小差不多相等的簇。
average链接:也称为均链接,将簇中所有点之间“平均距离”最小的两个簇合并。
complete链接:也称为最大链接,将簇中点之间“最大距离”最小的两个簇合并。
single链接:也称单链接,将簇中所有点之间“最小距离”最小的两个簇合并。
ward适用于大多数数据集。如果簇中的成员个数非常不同(比如其中一个比其他所有都大得多),那么average或complete可能效果更好。
3.2 程序
通过sklearn.cluster.AgglomerativeClustering算法实现。
from sklearn.cluster import AgglomerativeClusteringdef my_AgglomerativeClustering(): blobs = make_blobs(random_state=1,centers=1) X = blobs[0] y = blobs[1]#设置簇个数为3 AC = AgglomerativeClustering(n_clusters=3) result = AC.fit_predict(X) print("训练集数据集分配簇标签为:\n{}".format(AC.labels_)) print("对训练集数据集预测结果为:\n{}".format(result))
输出
训练集数据集分配簇标签为:[1 1 0 2 1 2 2 1 0 2 1 2 0 0 1 2 2 0 0 0 2 0 2 2 0 1 2 2 1 1 2 0 0 0 2 0 2 0 0 0 2 1 0 0 2 2 2 1 0 0 0 1 2 2 2 2 2 2 2 2 2 2 2 0 0 1 0 0 0 2 2 1 2 2 2 1 2 0 0 0 2 0 2 2 0 1 2 1 2 0 2 0 2 2 2 2 0 2 2 1]对训练集数据集预测结果为:[1 1 0 2 1 2 2 1 0 2 1 2 0 0 1 2 2 0 0 0 2 0 2 2 0 1 2 2 1 1 2 0 0 0 2 0 2 0 0 0 2 1 0 0 2 2 2 1 0 0 0 1 2 2 2 2 2 2 2 2 2 2 2 0 0 1 0 0 0 2 2 1 2 2 2 1 2 0 0 0 2 0 2 2 0 1 2 1 2 0 2 0 2 2 2 2 0 2 2 1]
最后我们还用凝聚聚类对iris数据进行聚类
def AgglomerativeClustering_for_iris(): X,y = datasets.load_iris().data,datasets.load_iris().target AC = AgglomerativeClustering(n_clusters=3) AC.fit(X) result = AC.fit_predict(X) print("iris原始数据集分配簇标签为:\n{}".format(y)) print("iris AC训练簇标签为:\n{}".format(result))
4 DBSCAN
4.1 概念
DBSCAN(Density-basedspatial clustering of application with nose):基于密度的有噪音应用空间聚类。密度大的地方是一类,密度小的地方是分界线。不需要事先指明簇的个数。
DBSCAN的算法如下:
while(存在没有被访问过的点) : 选择任意一个点for (遍历该点<eps的所有点) :if(点的个数<= min_sample): 标记为噪音(noise),这个点不属于任何簇else: 这个点标记为核心样本(核心点),分配一个簇标签for (该点在距离eps内的邻居) &&(邻居存在核心样本):if (没有分配一个簇): 将刚才创建的簇分配给它elif(核心样本) :依次访问它的邻居
所以,DBSCAN中有三个关键参数:
核心点;
核心点距离eps内的点(边界点);
噪音。
程序
基本概念
通过sklearn.cluster.DBSCAN算法实现。
照旧,我们首先来显示一下DBSCAN的散点图。
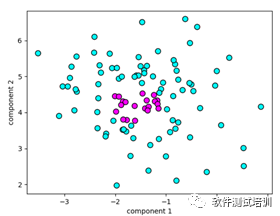
def my_dbscan(): db = DBSCAN()# 使用DBSCAN拟合 blobs = make_blobs(random_state=1,centers=1) x_blobs = blobs[0] clusters = db.fit_predict(x_blobs)#绘制散点图 plt.scatter(x_blobs[:,0],x_blobs[:,1],c=clusters,cmap=plt.cm.cool,s=60,edgecolor='k') plt.xlabel('component 1') plt.ylabel('component 2') plt.show()
输出
[-1 0 -1 0 -1 0 0 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 0 00 -1 0 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -10 0 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 -1 0 0 0 0 0 0 00 0 -1 -1 0 0 0 0 -1 0 0 -1 0 0 -1 0 0 0 0 0 0 0 0 -10 0 0 -1]
里面0 簇:紫色区域,-1为噪音点:蓝色区域。
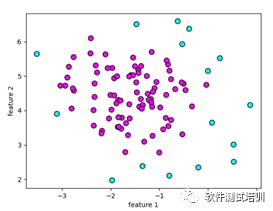
4.2.2 eps参数
eps指定划分为一簇样本的距离有多远,越大,聚类覆盖面越大(默认0.5)。
# 设置eps=2(默认为0.5),加大eps,簇变大db_1 = DBSCAN(eps=2)# 使用DBSCAN拟合 clusters_1 = db_1.fit_predict(x_blobs)#绘制散点图 plt.scatter(x_blobs[:,0],x_blobs[:,1],c=clusters_1,cmap=plt.cm.cool,s=60,edgecolor='k') plt.xlabel('component 1') plt.ylabel('component 2') plt.show()
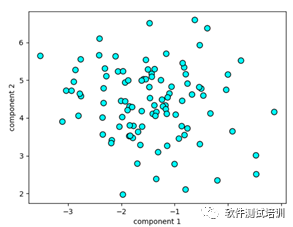
所有点都变成了一簇。
4.2.3 min_sample参数
min_sample聚类核心点的个数,min_sample越大,核心点个数越小,噪音也就越大; min_sample越小,核心点个数越多,噪音也就越少。默认min_sample=2。
# 设置min_samples =20(min_samples=2),min_samples越大,核心点个数越小,噪音也就越大db_2 = DBSCAN(min_samples=20)# 使用DBSCAN拟合 clusters_2 = db_2.fit_predict(x_blobs)#绘制散点图 plt.scatter(x_blobs[:,0],x_blobs[:,1],c=clusters_2,cmap=plt.cm.cool,s=60,edgecolor='k') plt.xlabel('component 1') plt.ylabel('component 2') plt.show()
我们通过以下代码进一步展示这两个参数的作用。
#绘制不同eps,min_sample下的DBSCAN分布mglearn.plots.plot_dbscan()plt.show()
输出
min_samples: 2 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]min_samples: 2 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]min_samples: 2 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]min_samples: 2 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]min_samples: 3 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]min_samples: 3 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]min_samples: 3 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]min_samples: 3 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]min_samples: 5 eps: 1.000000 cluster: [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]min_samples: 5 eps: 1.500000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]min_samples: 5 eps: 2.000000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]min_samples: 5 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
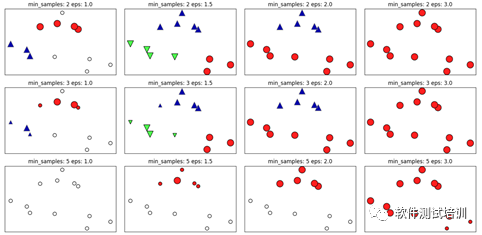
由此可见esp越大,越容易整体归为一类;min_samples越大,噪音越多。
4.2.4 用DBSCA分析两个月亮模型数据
from sklearn.datasets import make_moonsfrom sklearn.preprocessing import StandardScaler # 标准化工具from sklearn.cluster import DBSCAN X, y = make_moons(n_samples=200,noise=0.05, random_state=0)# 缩放数据 scaler = StandardScaler() scaler.fit(X) X_scaled = scaler.transform(X)# 打印处理后的数据形态 print("处理后的数据形态:",X_scaled.shape)# 处理后的数据形态: (200, 2) 200个样本 2类 dbscan = DBSCAN() clusters=dbscan.fit_predict(X_scaled)#绘制簇分配结果 plt.scatter(X_scaled[:,0],X_scaled[:,1],c=clusters,cmap=mglearn.cm2,s=60) plt.xlabel("Feture 0") plt.ylabel("Feture 1") plt.show()
输出
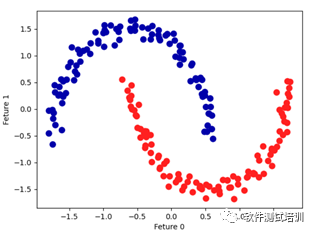
5.聚类比较
算法
特色
K均值
允许用户设定“簇”的数量
用簇平均值表示簇
凝聚
允许用户设定“簇”的数量
划分整个层次结构,通过树状图查看
DBSCAN
可以检测没有分配的噪音
允许用户设定eps定义接近程度,从而影响“簇”的大小
可以生成差别很大的两个“簇”
—————————————————————————————————
顾老师课程欢迎报名

软件安全测试
https://study.163.com/course/courseMain.htm?courseId=1209779852&share=2&shareId=480000002205486
接口自动化测试
https://study.163.com/course/courseMain.htm?courseId=1209794815&share=2&shareId=480000002205486
DevOps 和Jenkins之DevOps
https://study.163.com/course/courseMain.htm?courseId=1209817844&share=2&shareId=480000002205486
DevOps与Jenkins 2.0之Jenkins
https://study.163.com/course/courseMain.htm?courseId=1209819843&share=2&shareId=480000002205486
Selenium自动化测试
https://study.163.com/course/courseMain.htm?courseId=1209835807&share=2&shareId=480000002205486
性能测试第1季:性能测试基础知识
https://study.163.com/course/courseMain.htm?courseId=1209852815&share=2&shareId=480000002205486
性能测试第2季:LoadRunner12使用
https://study.163.com/course/courseMain.htm?courseId=1209980013&share=2&shareId=480000002205486
性能测试第3季:JMeter工具使用
https://study.163.com/course/courseMain.htm?courseId=1209903814&share=2&shareId=480000002205486
性能测试第4季:监控与调优
https://study.163.com/course/courseMain.htm?courseId=1209959801&share=2&shareId=480000002205486
Django入门
https://study.163.com/course/courseMain.htm?courseId=1210020806&share=2&shareId=480000002205486
啄木鸟顾老师漫谈软件测试
https://study.163.com/course/courseMain.htm?courseId=1209958326&share=2&shareId=480000002205486














