Ben Thomposn:“幽灵”与“熔毁”漏洞映射出了科技行业的现状
编者按:Ben Thomposn最近在博客上发表文章,对幽灵与熔毁背后的机制进行了详细的解释。并指出幽灵与熔毁的出现并不是偶然,而是当前科技行业的体制下必然会出现的一种现象。文章由36氪编译。

你应该听过这样一句格言:“一切都是1和0”,但这不是一个比喻:晶体管是计算机的基本组成部分,它只是一个开关,要么打开(“1”),要么关闭(“0”)。然而,事实证明,正如克里斯·迪克森(Chris Dixon )在一篇题为《亚里士多德如何创造计算机》的精彩文章中所写的,通过数学逻辑和晶体管的组合,1和0是你所需要的全部:
计算机的历史通常被认为是一个实物的历史,从算盘到巴贝奇差分机,再到二战时的密码分析机。实际上,把它理解为思想史会更好,那些思想主要诞生自数理逻辑——一门形成于19世纪,晦涩难懂、像邪教一样的学科。
迪克森的文章——我之前提到过——很值得一读,但这篇文章的相关观点也许是令人惊讶的:
计算机真的很愚蠢,它们之所以有用,是因为它们非常愚蠢。
处理器漏洞的问题
上周,科技行业因为现代处理器中的两个漏洞被披露而震惊了:熔毁(Meltdown)和幽灵(Spectre)。由于人们对这个漏洞性质的普遍猜测(可能是由Linux内核的更新引起的),以及熔毁和幽灵在某些方面是相似的,但在其他方面却有所不同。所以披露日期提前了一个星期。
从相似点开始:两个漏洞的结果都是一样的——非特权用户可以访问他们不应该访问的计算机上的信息,比如密钥、密码或其他用户拥有的任何其他类型的数据。对于AWS这样的云服务来说,这是一个特别大的问题。在AWS上,多个“租户”使用的是相同的物理硬件:
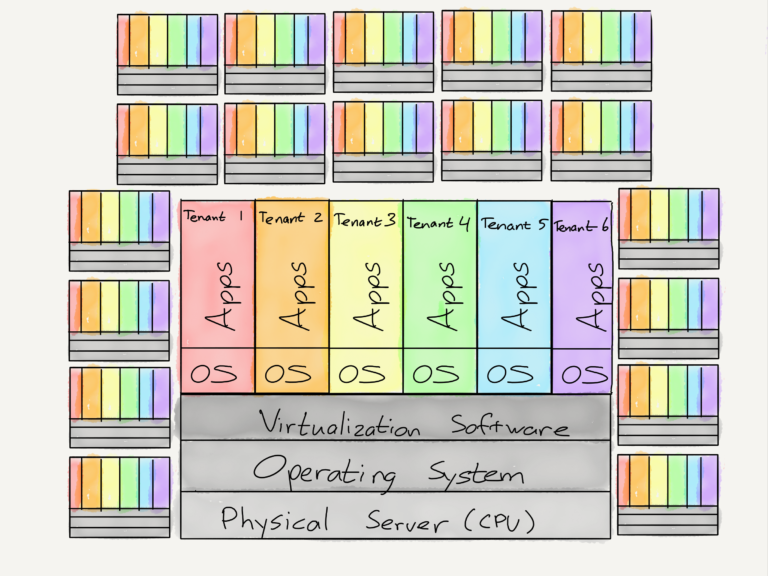
这种多租户架构是通过使用虚拟机实现的:在一台物理计算机上运行的专用软件,可以让每一个用户都像拥有自己的计算机一样操作,而实际上它们是共享的。这是一种双赢的做法:在绝大多数情况下,单个用户的计算机都处于闲置状态(它们很快就会变得愚蠢),如果多个用户使用一台计算机,那么硬件的使用效率将会大大提高。而且,在云服务领域,同样的概念可以扩展到数百万台物理计算机,共享更多的基础设施,比如冷却、网络、管理等。
不过,整个体系的建立基于一个基本假设:一台虚拟机的用户不能访问另一台虚拟机的数据。这一假设的扩展依赖于对虚拟机软件的完整性的信任,这种信任依赖于对底层操作系统完整性的信任,最终依赖于对服务器核心处理器的信任。来自熔毁的白皮书(强调是作者加的):
为了将数据从主存储器加载到寄存器中,主存储器中的数据就要通过虚拟地址来引用。在将虚拟地址转换为物理地址的同时,CPU还会检查虚拟地址的权限位,也就是说,这个虚拟地址用户是否能够访问,或者只能由内核访问。正如在第2.2节中已经讨论过的,这种通过权限位的基于硬件的隔离被认为是安全的,并且是由硬件供应商推荐的。因此,现代操作系统总是将整个内核映射到每个用户进程的虚拟地址空间。因此,所有内核地址在翻译它们时都会产生一个有效的物理地址,并且CPU可以访问这些地址的内容。访问用户空间地址的唯一不同之处在于,CPU会引发异常,因为当前权限级别不允许访问这样的地址。因此,用户空间不能简单地读取这样一个地址的内容。
内核是操作系统的核心部分,正常用户应该无法访问,它有自己的内存,不仅存储核心系统数据,还存储来自所有用户的数据(例如,必须将其写入或从永久存储中读取)。不过,即使在这里,系统也依赖于虚拟化——内存是用户在应用程序中使用的物理内存,这取决于CPU,以便跟踪内存的哪些部分属于谁,而这正是漏洞所在之处。
SPECULATIVE_EXECUTION
我刚刚只是提到了电脑的三个关键部分:处理器、内存和永久存储。事实上,存储数据的架构比这更复杂:
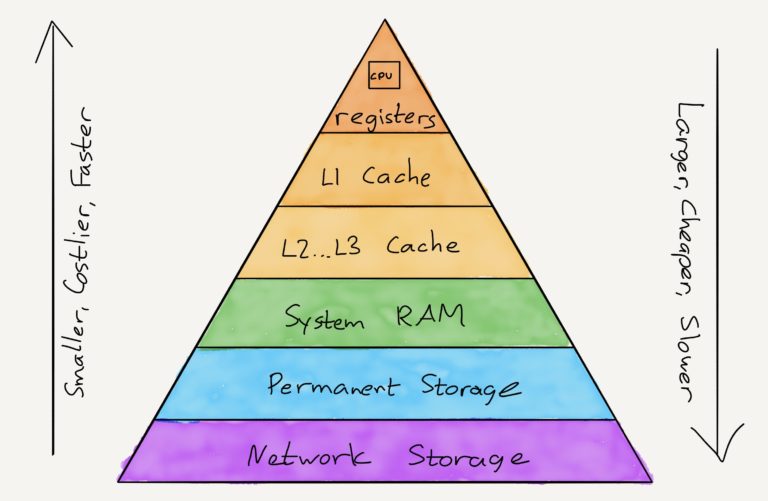
寄存器是最快的内存形式,每个时钟周期都可以访问(也就是说,2.0 GHz的处理器每秒可以访问寄存器20亿次)。它们也是最小的,通常只包含当前计算的输入和输出。
然后有各种各样的缓存(L1、L2等),它们的速度越来越慢,而且在另一方面,越来越大,也越来越便宜。这种缓存位于一个层次结构中:例如,立即需要的数据将会从寄存器移到L1缓存;稍微不那么必要的数据将位于L2,然后是L3等等。
内存层次结构的下一个主要部分是主存,即系统RAM。虽然缓存的数量取决于处理器模型,但内存的总量取决于整个系统生成器。这种内存比高速缓存慢得多,但它也比缓存大得多,而且便宜得多。
内存层次结构的最后一部分,至少在一台计算机上是永久存储——硬盘驱动器。固态硬盘(SSD硬盘)在这里的速度有很大的不同,但即便如此,永久存储的速度也比主内存慢得多,但也存在同样的问题:你可以以更低的价格获得更多的存储空间。
虽然不属于传统的内存层次结构的一部分,但云应用程序通常在同一网络上的独立物理服务器上拥有永久的内存,通常的折衷方案是——非常缓慢的访问以换取其他好处,在这种情况下,将数据与应用程序分开。
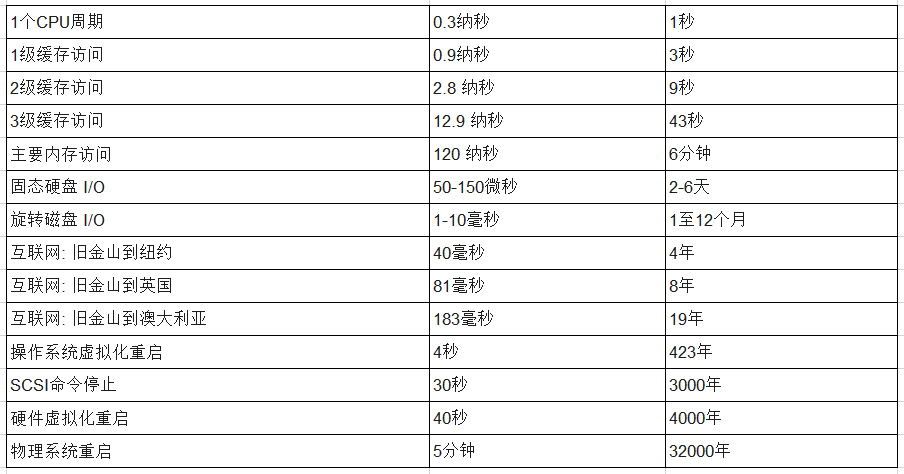
可以肯定的是,“非常慢”是相对的——我们在这里讨论的是纳秒。
杰夫·阿特伍德(Jeff Atwood)的这篇文章用人类的语言来描述就是:
在我们人类的感觉中,无限空间是计算机花费所有时间的地方。这是一个完全不同的时间跨度。系统性能:企业和云计算有一个很好的表格,说明了这些时间差异有多么巨大。只要把计算机时间转换成任意的秒钟即可:
已故的吉姆·格雷(Jim Gray)也有一种有趣的解释方式。如果CPU寄存器是你从你的大脑获取数据需要的时间,那么进入磁盘就相当于从冥王星获取数据。
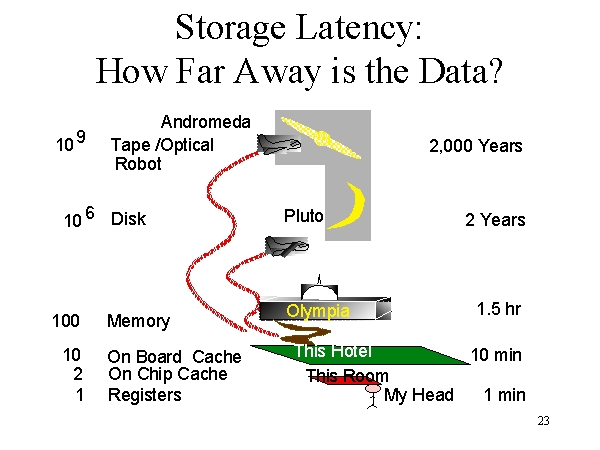
格雷在微软的演讲中展示了这张幻灯片,给出了“华盛顿,奥林匹亚”的背景信息。让我把他的类比扩展一下:
假设你是一名大学生,在微软实习,当时你在奥林匹亚的家里收拾衣服。现在,西雅图的夏天可能非常挑剔——可能是狂风大作、下雨的天气,或者是炎热和阳光的天气。要想知道明天早上的天气会是什么样子,通常是很难的。为了实现这一目标,谨慎的做法不是只打包一套衣服,而是为了两种可能而打包衣服。毕竟,每次天气变化,从行李箱里换衣服要比开车回家要快得多。
这就是这个类比开始瓦解的地方:现代处理器为了减少获取数据所需要的时间,不仅获取了超出需要的数据,而且还会提前对这些数据进行计算。这就是所谓的Speculative_execution,也是这些漏洞的核心所在。用算法的形式来类比:
检查天气(执行多个触发传感器、中继数据等的多个子进程)。
如果天气晴朗,穿短袖和T恤
其他的天气,穿牛仔裤和运动衫
记住,电脑是愚蠢的,但速度很快:执行“穿短袖和T恤”或“穿牛仔和运动衫”需要纳秒——需要时间就是等待天气观察的结果。所以为了节省时间,处理器会在它了解天气之前帮你穿衣,这通常是基于历史的——过去几天的天气是怎样的?这意味着你可以在等待天气观察结果的同时,决定鞋子、配饰等。这是处理器的另一个特点:它们可以同时做很多事情。为了实现这一目标,最快的完成任务的方法就是猜测最终的结果是什么,如果有必要,还会进行回溯。
熔毁
现在,想象一下这个算法被修改成以下的内容:
检查经理的日程表,看看他们是否在办公室
如果他们在办公室,穿宽松的裤子和衬衫
如果他们不在办公室,穿短裤和T恤
只有一个问题:你不应该接触到你经理的日程表。请记住,计算机是愚蠢的:处理器不知道这一点,它必须检查你是否有访问权限。所以在实践中,这个算法更像这样:
检查经理的日程表,看看他们是否在办公室
检查一下这个实习生是否能访问他们经理的日程表
如果实习生有权限,可以访问日程表
如果经理在办公室,穿宽松的裤子和衬衫
如果他们不在办公室,穿短裤和T恤
如果实习生没有权限,就不要穿衣服了
不过请记住,计算机虽然很擅长同时处理大量的事情以及在查询数据上并不是很擅长,在这种情况下,处理器会在特定条件下查看经理的日程表,并在它知道对方是否有权限查看日程表之前,决定应该穿什么。如果它后来意识到对方不应该有访问日程表的权限,它会毁掉一切,但是衣服可能会被弄得有点凌乱,这意味着你可以得到你不应该知道的答案。
我已经说过,这个类比已经瓦解了,它现在已经彻底崩溃了。但这在广义的描述中:处理器会在它知道它是否有权限的情况下,投机性地获取和执行特权数据,这个过程在缓存中留下了痕迹,那些痕迹可以被非特权用户捕捉到。
解释幽灵
幽灵更加狡猾,但更难实现:记住,很多用户都在使用相同的处理器——他们都是你的“室友”,如果你愿意的话。假设我像你一样打包行李箱,然后我“训练”处理器,让它一直期待晴天(也许我可以运行一个模拟程序,让每一天都充满阳光)。处理器将会提前选择短裤和T恤。然后,当你醒来的时候,处理器已经选择了短裤和T恤,如果真的是雨天,它会把短裤和T恤放回去,但会显得有点凌乱。
这个类比在这里真的行不通。你的数据并不是简单地从主存储器中提取出来的,它会暂时保存在缓存中,而处理器会在错误的分支上运行,一旦处理器修复了错误,它就会被迅速删除,但我仍然能弄清楚数据是什么——这意味着我现在已经窃取了你的数据。
熔毁更容易解释——英特尔的声明恰恰与之相反(熔毁也会影响苹果的处理器)——这是由于设计缺陷造成的。处理器负责检查是否可以被访问数据,并且检查速度过慢,这样数据就会被窃取,这是一个错误。这也解释了为什么熔毁可以在软件中运行(基本上,在使用数据之前会有一个额外的步骤检查权限,这就是为什么补丁会导致性能下降)。
幽灵完全是另外一回事:这是处理器的设计。计算机的基本运算速度快得令人难以理解,但是需要花费很长时间才能得到这些数据来进行这些计算:因此,在不等待瓶颈的情况下进行计算,基于最佳猜测,是利用这种基本不平衡的最佳方式。大多数情况下,你会更快地得到结果,如果你猜错了,你的速度也不会比你按顺序完成所有事情的情况慢。
这也解释了为什么幽灵会影响所有的处理器:利用现代处理器的并行度和执行速度带来的快速增长是如此巨大,以至于Speculative_execution是一个显而易见的选择。分支预测器可能会被另一个用户训练,这样缓存变化就可以被跟踪,直到去年才被我们知道。
此外,幽灵党不能通过软件来修复:具体的实现可以被阻止,但漏洞是内置的,想要彻底解决,需要重新设计新的处理器,但这对已经在使用的数十亿处理器不会有任何作用。我们将不得不勉强度日。
幽灵与科技现状
有个类比是显而易见的:面对一个根本性的不平衡(相对于快速迭代与优化程序来说,获取和保留用户的难度非常大),互联网公司设计出了加强用户留存的巧妙系统,但未能预见到坏人滥用系统的可能性,每个人都很容易受到攻击。
不过,幽灵有助于解释这些问题为何如此令人烦恼:
我不相信有人会故意制造这种漏洞
这个漏洞可能是值得的——更快的处理器会带来更大的好处
无论如何,过去的决定都是过去的:我们能做的最好的事情就是得过且过
因此,对Facebook、谷歌/Youtube等网站,以及互联网带来的广泛负面影响的处理也会如此。权力来自于给予人们他们想要的东西——这个动机并不是坏的!而它带来的好处,可能超过了其负面影响。无论如何,我们唯一的选择就是继续往前走。
原文链接:https://stratechery.com/2018/meltdown-spectre-and-the-state-of-technology/
编译组出品。编辑:郝鹏程













